*틀린 내용이 있을 경우 댓글로 알려주신다면 감사하겠습니다!
먼저 프로그래밍 언어와 컴퓨터가 이해하는 언어를 말하고자 합니다. 사람이 이해하고 작성하기 쉽게 만들어진 언어를 '고급 언어'(자바, 파이썬, C, ...)라 하고, 컴퓨터가 이해하고 실행할 수 있는 언어를 '저급 언어'(기계어, 어셈블리어)라 합니다. 저급 언어는 명령어로 이루어져 있기에, 고급 언어로 작성된 프로그램 코드를 컴퓨터가 이해하기 위해선 저급 언어로 변환하는 과정을 거쳐야 합니다.
기계어는 0과 1의 명령어 비트로 이루어진 명령어 모음으로, 오로지 컴퓨터만이 알 수 있게 만들어진 언어이기에 사람은 이해하기 힘듭니다. 그래서 기계어를 읽기 조금 편하게 나온 언어가 어셈블리어입니다.
고급 언어를 저급 언어로 변환하는 과정이 있다 했는데, 컴파일 방식으로 변환 과정을 거치는 고급 언어를 컴파일 언어. 인터프리트 방식으로 변환 과정을 거치는 고급 언어를 인터프리터 언어라 합니다.
- 컴파일 언어
: 컴파일러에 의해 소스 코드 전체가 저급 언어로 변환되어 실행되는 고급 언어를 의미합니다. 이 변환 과정을 '컴파일(compile)'이라 하고, 이를 수행해주는 도구를 '컴파일러(compiler)'라고 합니다. 컴파일 언어의 대표적인 것으로 C가 있습니다.
소스 코드 전체를 살펴보고, 문법적인 오류가 있는지 아니면 실행 가능한 코드인지 혹은 불필요한 코드가 있는지 확인합니다. 만약 오류가 하나라도 있으면 컴파일에 실패합니다.
컴파일러를 통해 저급 언어로 변환된 코드를 '목적 코드(object code)'라 합니다.
- 인터프리터 언어
: 인터프리터에 의해 소스 코드가 한 줄씩 실행되는 고급 언어를 의미합니다. 대표적인 언어로 파이썬이 있습니다.
컴파일 언어와 달리, 인터프리터 언어는 소스 코드를 한줄씩 차례대로 실행합니다. 그리고 한줄씩 저급 언어로 변환시키는데 이를 해주는 도구가 '인터프리터(interpreter)'입니다. 그리고 오류 발생 시, 컴파일 언어와 다르게 오류 있는 코드 바로 직전 코드까지 실행합니다.
참고1) "고급언어에서 저급언어로의 변환 방식이 두 종류 있다"로 이해하기
프로그래밍 언어가 반드시 컴파일 언어, 인터프리터 언어 둘 중 하나로만 있는 게 아님. 딱 잘라 한 가지 방식으로만 작동되는 언어도 있지만 그렇지 않은 경우도 있음. 파이썬도 컴파일 하는 경우 있고, 자바도 컴파일과 인터프리트 동시 수행.
참고2) 목적 파일 vs 실행 파일
목적 코드로 이루어진 파일을 '목적 파일'이라 함. 실행 코드로 된 파일을 '실행 파일'이라 함. 두 파일은 같은 것이 아님. 목적 코드가 실행 파일이 되기 위해 '링킹' 작업 필요.
예) C언어로 작성된 main.c와 helper.c란 코드가 존재.
main.c : helper.c에 있는 HELPER_값_입력하기, 화면_출력 라이브러리가 코드로 작성됨.
helper.c : HELPER_값_입력하기 코드 존재.
두 코드를 각각 컴파일하면 두 개의 목적 파일 생성됨. main.o와 helper.o로. 여기서 main.o는 c코드를 단순히 저급 언어로 변환했을 뿐, '화면 출력'이나 'HELPER_값_입력하기'를 모르기 때문에 실행 불가. 이렇게 main.o에 없는 외부 기능을 연결 짓는 작업(링킹)이 필요.
- 명령어 구조
: 명령어는 '무엇을 대상으로', '어떤 작동을 수행하라'로 구성됐다 말할 수 있습니다.
구조를 더 자세히 말하자면 [명령어=연산코드+오퍼랜드] 형태로 되어 있습니다.

- 연산 코드(operation code)
: 명령어가 수행할 연산, 즉 '연산자'를 의미합니다. 연산 코드가 담기는 영역을 '연산 코드 필드'라 부릅니다.
기본적인 연산 코드 유형에는 '데이터 전송', '산술/논리 연산', '제어 흐름 변경', '입출력 제어'가 있습니다.
- 오퍼랜드(operand)
: 연산에 사용할 데이터, 데이터가 저장된 위치를 의미합니다. 피연산자라고 할 수 있습니다. 오퍼랜드가 들어가는 영역을 '오퍼랜드 필드'라 부릅니다. 오퍼랜드 필드에 숫자와 문자 등을 나타내는 데이터 혹은 메모리, 레지스터 주소가 들어갈 수 있습니다. 그러나 데이터를 직접 명시하기보다는 그 데이터가 저장된 메모리 주소나 레지스터 이름을 활용합니다. 이런 이유로 '주소 필드'라고도 합니다.
오퍼랜드는 하나도 없을 수도 있고, 하나 이상이 있을 수도 있습니다. 오퍼랜드가 하나도 없는 명령어를 '0-주소 명령어', 오퍼랜드가 1개인 명령어를 '1-주소 명령어'라 합니다(오퍼랜드가 두 개, 세 개일 때도 같은 형태로 표현).
- 주소 지정 방식
: 오퍼랜드 필드에는 연산에 사용될 데이터를 직접 명시하지 않는다 했습니다. 그 이유는 명령어 길이 제한 때문입니다. 하나의 명령어는 n비트로 구성되고, 연산 코드 필드가 m비트라 할 때 오퍼랜드 필드에서 사용할 수 있는 비트는 n-m 비트입니다. 오퍼랜드 필드 수가 늘어날수록 하나당 사용할 수 있는 비트 수가 줄어들 겁니다. 그래서 오퍼랜드 필드에는 메모리 주소나 레지스터 이름을 쓰는 것입니다.
연산 코드에 사용할 데이터가 저장된 위치를 '유효 주소(effective address)'라 합니다. 이렇게 오퍼랜드 필드에 데이터가 저장된 위치를 명시할 때 연산에 사용할 데이터 위치를 찾는 방법을 '주소 지정 방식'이라 말힙니다. 유효 주소를 찾는 방법인 것이죠.
CPU는 다양한 주소 지정 방식을 사용하는데 그 대표적인 종류를 아래에 정리하고자 합니다.
- 즉시 주소 지정 방식(immediate addressing mode)
: 연산에 사용할 데이터를 오퍼랜드 필드에 직접 명시하는 방식입니다. 앞서 이 방식의 단점을 적었는데, 아무래도 메모리나 레지스터로부터 데이터를 찾는 과정이 없어서 그런지 다른 방식들보다 속도에서는 빠릅니다.

- 직접 주소 지정 방식(direct addressing mode)
: 오퍼랜드 필드에 유효 주소를 직접적으로 명시하는 방식입니다. 즉시 주소 지정 방식보다는 오퍼랜드 필드에서 표현 가능한 범위가 커졌으나, 연산 코드 길이만큼 길이가 짧아집니다.

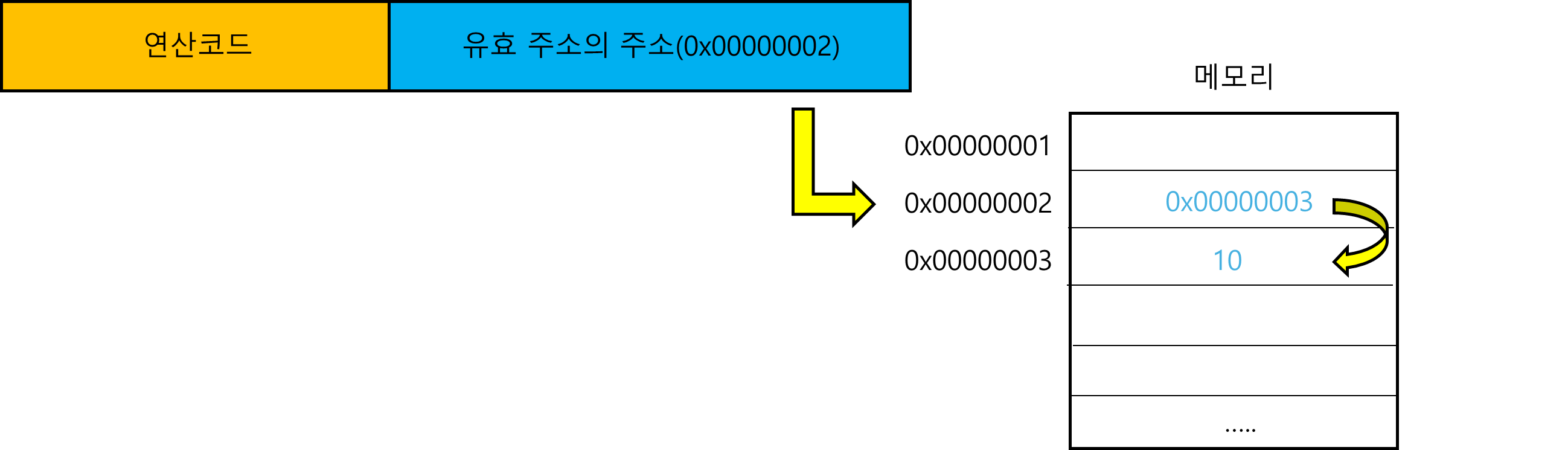
- 간접 주소 지정 방식(indirect addressing mode)
: 유효 주소의 주소를 오퍼랜드 필드에 명시하는 방식입니다. 이 방식에는 두 번의 메모리 접근이 필요하다는 단점이 있습니다.
- 레지스터 주소 지정 방식(register addressing mode)
: 연산에 사용할 데이터를 저장한 레지스터를 오퍼랜드 필드에 직접 명시하는 방식입니다.

- 레지스터 간접 주소 지정 방식(register indirect addressing mode)
: 연산에 사용할 데이터를 메모리에 저장하고, 그 유효 주소를 저장한 레지스터를 오퍼랜드 필드에 명시하는 방식입니다. 간접 주소 지정 방식과 비슷하지만, 메모리 접근 횟수가 한 번이라는 차이가 있습니다. 메모리에 접근하는 것이 레지스터에 접근하는 것보다 느리기에, 레지스터 간접 주소 지정 방식이 간접 주소 지정 방식보다 빠릅니다.

'컴퓨터 구조' 카테고리의 다른 글
| Ch04 CPU의 작동 원리 (1) | 2024.08.10 |
|---|---|
| Ch01~02 컴퓨터 구조 시작하기-데이터 (5) | 2024.08.02 |
| 공부 계획 (0) | 2023.08.19 |

